高级选项☍
Warning
如果你是整合包用户,非必要情况下请勿使用启动器的 高级 / 专家 模式。如有必要,请务必在调整设定前记录好原本设定的值(除非您的 SD WebUI 已无法正常使用)。
一般绘世启动器常用的功能就是一键启动,而且高级选项里的参数默认已经被绘世启动器设置好。但是有时候需要调整一些关于 SD WebUI / ComfyUI / ... 的设置,这时候就可以通过修改高级选项来调整。
修改高级选项需谨慎,如果因为修改了高级选项导致出现问题,请点击高级选项右上角的恢复默认设置,这样就会把所有的设置恢复成默认。
如果只想恢复单个设置,可以点击设置旁边的箭头。

Note
以下选项在绘世启动器的默认配置模式中有部分不会显示,需要在绘世启动器的设置->配置模式将新手改为专家。
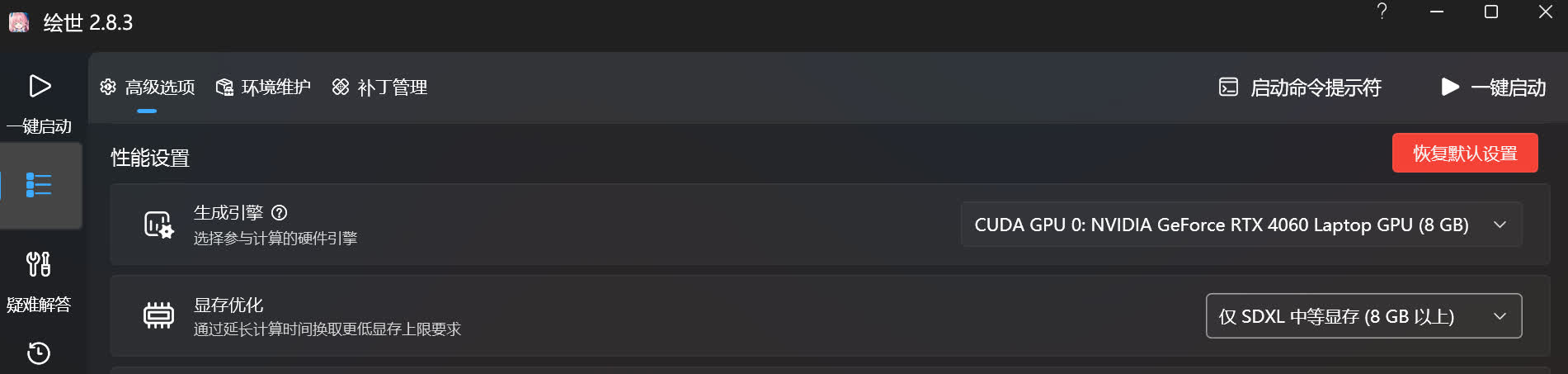
性能设置☍
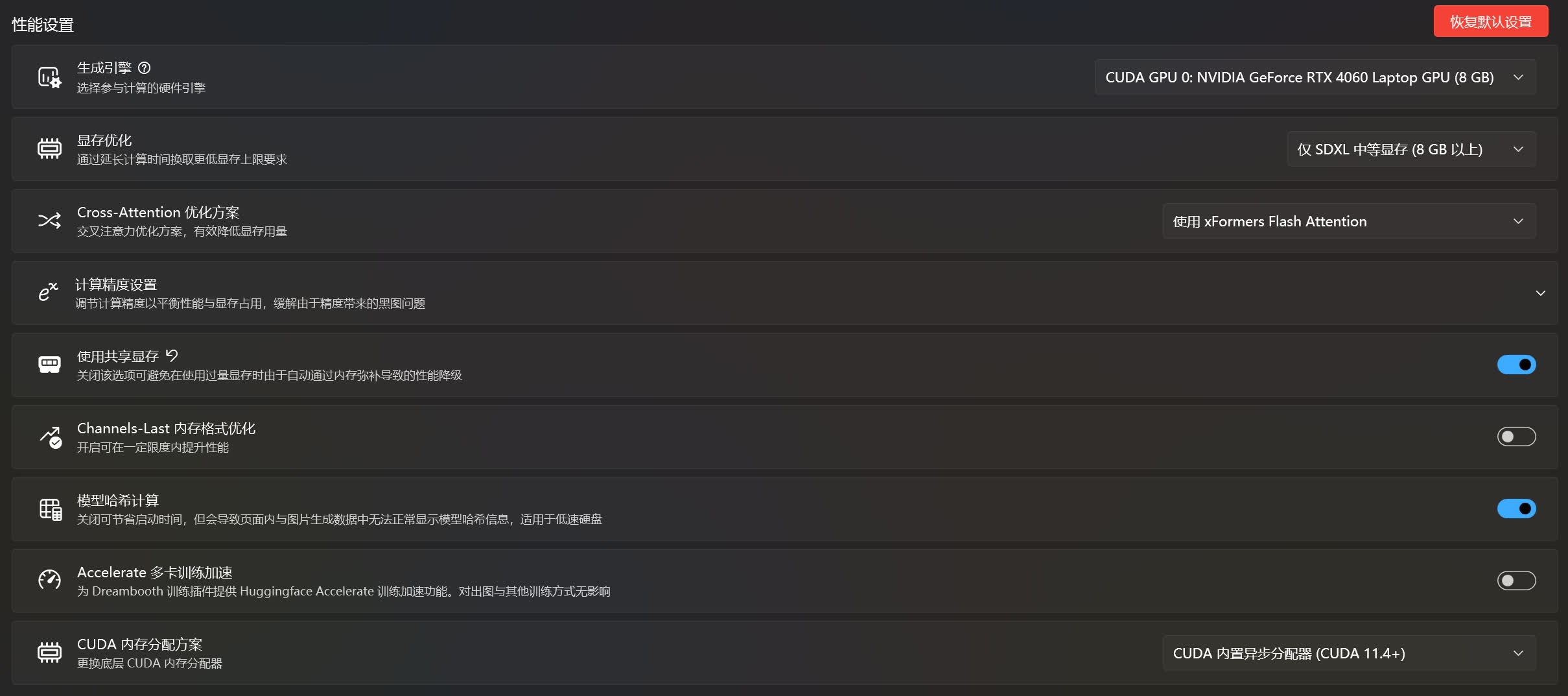
生成引擎☍
这是选择跑图是所使用的设备(CPU / 显卡),可以使用的设备将会被列举出来,并且只能选择一个。如果在这个列表中看不到自己想要选择的设置,可能有以下几种可能。
- 显卡驱动未正确安装或者显卡驱动未更到最新,建议前往显卡驱动官网下载最新的驱动并安装。
- PyTorch 版本不对或者未正确安装,需要在绘世启动器的
高级选项->环境维护->安装 PyTorch重新安装 PyTorch。 - Stable Diffusion 项目的分支不对,需要在绘世启动器的
版本管理->内核->切换分支,选择正确的分支并切换。比如显卡型号是 AMD,并且只支持使用 DirectML,但是分支是AUTOMATIC1111/stable-diffusion-webui,此时就需要将分支切换至lshqqytiger/stable-diffusion-webui-directml或者vladmandic/automatic。 - 设备(显卡)本身不支持,这种情况只能更换设备了(CPU 跑图那么慢,应该没人愿意用 CPU 跑图吧)。
Info
该选项使用CUDA_VISIBLE_DEVICES环境变量指定 Nvidia 显卡,HIP_VISIBLE_DEVICES环境变量指定 AMD 显卡,ONEAPI_DEVICE_SELECTOR指定 Intel 显卡。
显存优化☍
这是调整 SD WebUI / ComfyUI / ... 对显存的优化方案,一般要根据自己显卡的显存来选择。
比如显卡的显存为 8 GB,这时候就要选择对应的仅 SDXL 中等显存 (8 GB 以上)选项,或者比这个选项更低的选项,不然容易出现爆显存的问题。
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:
- 无优化 (12 GB 以上):无对应参数
- 仅 SDXL 中等显存 (8 GB 以上):
--medvram-sdxl - 中等显存 (4 GB 以上):
--medvram - 低显存 (不足 4 GB):
--lowvram - 全显存 (不推荐):
--lowram
- SD WebUI AMDGPU:
- 无优化 (12 GB 以上):无对应参数
- 仅 SDXL 中等显存 (8 GB 以上):
--medvram-sdxl - 中等显存 (4 GB 以上):
--medvram - 低显存 (不足 4 GB):
--lowvram - 全显存 (不推荐):
--lowram
- SD WebUI Forge:
- 由 Forge 决定:无对应参数
- 无优化 (8 GB 以上):
--always-high-vram - 标准优化 (4 GB 以上):
--always-normal-vram - 低显存 (不足 4 GB):
--always-low-vram - 极低显存 (不足 2 GB):
--always-no-vram - 全显存 (不推荐):
--always-gpu
- SD Next:
- 无优化 (12 GB 以上):无对应参数
- 仅 SDXL 中等显存 (8 GB 以上):无对应参数
- 中等显存 (4 GB 以上):
--medvram - 低显存 (不足 4 GB):
--lowvram - 全显存 (不推荐):
--lowram
- ComfyUI:
- 由 ComfyUI 决定:无对应参数
- 无优化 (8 GB 以上):
--highvram - 标准优化 (4 GB 以上):
--normalvram - 低显存 (不足 4 GB):
--lowvram - 极低显存 (不足 2 GB):
--novram - 全显存:
--gpu-only
- Fooocus:
- 由 Fooocus 决定:无对应参数
- 无优化 (8 GB 以上):
--always-high-vram - 标准优化 (4 GB 以上):
--always-normal-vram - 低显存 (不足 4 GB):
--always-low-vram - 极低显存 (不足 2 GB):
--always-no-vram - 全显存:
--always-gpu
批量应用模型输入调整☍
恢复显存优化开启时停用得批量模型输入调整,修复部分 ControlNet/LoRA 问题。
Note
该选项仅在 SD Next 中出现。
Info
不清楚对应得启动参数是什么www~
Cross Attension 优化方案☍
这是调整在跑图时使用的优化方案,不同的方案对显存占用的优化不同,出图的速度也不同,xFormers 方案减少显存占用比较低,SDP 方案占用显存会高点,但是速度比 xFormers 方案快一点。
Note
更多对 Cross Attension 优化方案的说明可以参考 SD WebUI wiki:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Optimizations
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:
- 尝试使用 xFormers (推荐):
--xformers - 强制使用 xFormers:
--xformers --force-enable-xformers - 使用 xFormers Flash Attension:
--xformers --xformers-flash-attention - 使用缩放点积 (SDP) 方案:
--opt-sdp-attention - 使用无高效内存优化的缩放点积 (SDP) 方案:
--opt-sdp-no-mem-attention - 使用 Sub-Quadratic 方案:
--opt-sub-quad-attention - 自动 (推荐):无对应参数
- 强制使用 Deggettx 方案:
--opt-split-attention - 强制使用 InvokeAI 方案:
--opt-split-attention-invokeai - 使用旧版 (Split) 优化方案:
--opt-split-attention-v1 - 无优化 (不推荐):
--disable-opt-split-attention
- 尝试使用 xFormers (推荐):
- SD WebUI AMDGPU:
- 尝试使用 xFormers (推荐):
--xformers - 强制使用 xFormers:
--xformers --force-enable-xformers - 使用 xFormers Flash Attension:
--xformers --xformers-flash-attention - 使用缩放点积 (SDP) 方案:
--opt-sdp-attention - 使用无高效内存优化的缩放点积 (SDP) 方案:
--opt-sdp-no-mem-attention - 使用 Sub-Quadratic 方案:
--opt-sub-quad-attention - 自动 (推荐):无对应参数
- 强制使用 Deggettx 方案:
--opt-split-attention - 强制使用 InvokeAI 方案:
--opt-split-attention-invokeai - 使用旧版 (Split) 优化方案:
--opt-split-attention-v1 - 无优化 (不推荐):
--disable-opt-split-attention
- 尝试使用 xFormers (推荐):
- SD WebUI Forge:
- 尝试使用 xFormers (推荐):
--xformers - 使用缩放点积 (SDP) 方案:
--attention-pytorch --disable-xformers - 使用 Sub-Quadratic 方案:
--attention-quad --disable-xformers - 使用旧版 (Split) 优化方案:
--attention-split --disable-xformers
- 尝试使用 xFormers (推荐):
- SD Next:
- 尝试使用 xFormers (推荐):无对应参数
- 强制使用 xFormers:无对应参数
- 使用 xFormers Flash Attension:无对应参数
- 使用缩放点积 (SDP) 方案:无对应参数
- 使用无高效内存优化的缩放点积 (SDP) 方案:无对应参数
- 使用 Sub-Quadratic 方案:无对应参数
- 自动 (推荐):无对应参数
- 强制使用 Deggettx 方案:无对应参数
- 强制使用 InvokeAI 方案:无对应参数
- 使用旧版 (Split) 优化方案:无对应参数
- 无优化 (不推荐):无对应参数
- ComfyUI:
- 尝试使用 xFormers (推荐):无对应参数
- 使用 Sage Attention:
--use-sage-attention - 使用缩放点积 (SDP) 方案:
--use-pytorch-cross-attention - 使用 Sub-Quadratic 方案:
--use-quad-cross-attention - 使用旧版 (Split) 优化方案:
--use-split-cross-attention
- Fooocus:
- 尝试使用 xFormers (推荐):无对应参数
- 使用缩放点积 (SDP) 方案:
--attention-pytorch - 使用 Sub-Quadratic 方案:
--attention-quad - 使用旧版 (Split) 优化方案:
--attention-split
计算精度设置☍
这是用于调节 AI 在运算时使用的精度。
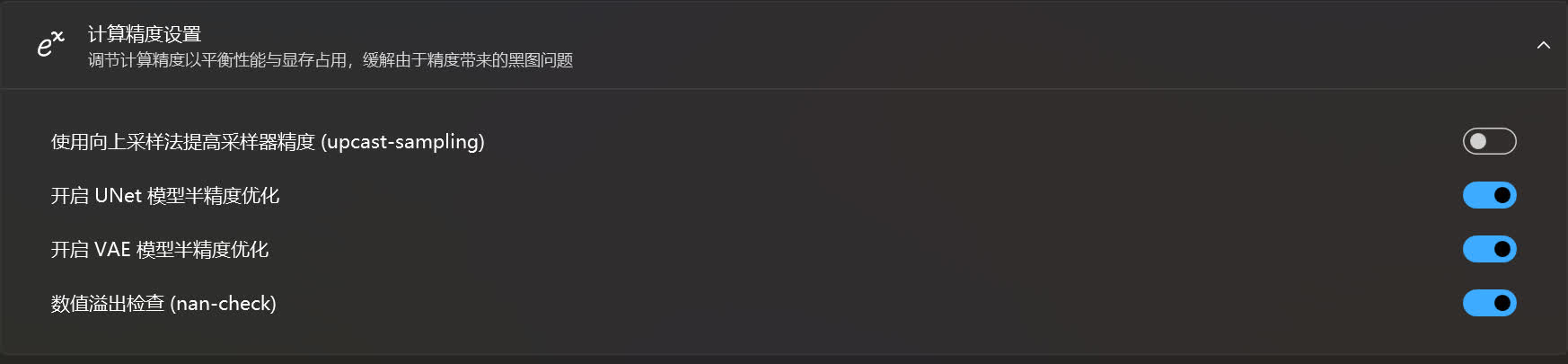
如果在跑图时经常报错提示在 UNet / VAE 中出现 NaN,可以选择关闭对应的模型半精度优化来缓解,但这可能会大大增加显存的占用量,出图的速度也会降低。通常通过更换模型来解决 NaN 更好。
数据溢出检查用于检测是否出现 NaN,如果想禁用 NaN 提示,可选择关闭该选项,这样即使偶尔出现 NaN 时也不会中断生图(这时会直接输出一张黑图)。
在对半精度不支持或支持太差的硬件上启用向上采样法提高采样器精度可能会提高速度。
Note
- 关闭
开启 UNet 模型半精度优化选项后,使用向上采样法提高采样器精度(upcast-sampling)选项会被自动禁用。 - 关于向上采样法的说明:--upcast-sampling support for CUDA by FNSpd · Pull Request #8782 · AUTOMATIC1111/stable-diffusion-webui
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:
- (启用时) 使用向上采样法提高采样精度 (upcast-sampling):
--upcast-sampling - (禁用时) 开启 UNet 模型半精度优化:
--no-half - (禁用时) 开启 VAE 模型半精度优化:
--no-half-vae - (禁用时) 数值溢出检查 (nan-check):
--disable-nan-check
- (启用时) 使用向上采样法提高采样精度 (upcast-sampling):
- SD WebUI AMDGPU:
- (启用时) 使用向上采样法提高采样精度 (upcast-sampling):
--upcast-sampling - (禁用时) 开启 UNet 模型半精度优化:
--no-half - (禁用时) 开启 VAE 模型半精度优化:
--no-half-vae - (禁用时) 数值溢出检查 (nan-check):
--disable-nan-check
- (启用时) 使用向上采样法提高采样精度 (upcast-sampling):
- SD WebUI Forge:
- 使用向上采样法提高 XAttn 精度 (upcast-attention):
- 自动:无对应参数
- 强制:
--force-upcast-attention - 禁用:
--disable-attention-upcast
- 通常模型精度:
- 由 Forge 决定:无对应参数
- 全精度 (FP32):
--all-in-fp32 --no-half - 半精度 (FP16):
--all-in-fp16
- 文本编码器 (Text Encoder) 模型精度:
- 由 Forge 决定:无对应参数
- 全精度 (FP32):
--clip-in-fp32 - 半精度 (FP16):
--clip-in-fp16 - FP8 (E4M3FN):
--clip-in-fp8-e4m3fn - FP8 (E5M2):
--clip-in-fp8-e5m2
- U-Net 模型精度:
- 由 Forge 决定:无对应参数
- BF16:
--unet-in-bf16 - 半精度 (FP16):
--unet-in-fp16 - FP8 (E4M3FN):
--unet-in-fp8-e4m3fn - FP8 (E5M2):
--unet-in-fp8-e5m2
- VAE 模型精度:
- 由 Forge 决定:无对应参数
- 全精度 (FP32):
--fp32-vae - 半精度 (FP16):
--vae-in-fp16 - BF16:
--vae-in-bf16
- 使用向上采样法提高 XAttn 精度 (upcast-attention):
- SD Next:
- (启用时) 使用向上采样法提高采样精度 (upcast-sampling):无对应参数
- (禁用时) 开启 UNet 模型半精度优化:无对应参数
- (禁用时) 开启 VAE 模型半精度优化:无对应参数
- (禁用时) 数值溢出检查 (nan-check):无对应参数
- ComfyUI:
- (禁用时) 使用向上采样法提高 XAttn 精度 (upcast-attention):
--dont-upcast-attention - 通常模型精度:
- 由 ComfyUI 决定:无对应参数
- 全精度 (FP32):
--force-fp32 - 半精度 (FP16):
--force-fp16
- 文本编码器 (Text Encoder) 模型精度:
- 由 ComfyUI 决定:无对应参数
- 全精度 (FP32):
--fp32-text-enc - 半精度 (FP16):
--fp16-text-enc - FP8 (E4M3FN):
--fp8_e4m3fn-text-enc - FP8 (E5M2):
--fp8_e5m2-text-enc
- U-Net 模型精度:
- 由 ComfyUI 决定:无对应参数
- BF16:
--bf16-unet - 半精度 (FP16):
--fp16-unet - FP8 (E4M3FN):
--fp8_e4m3fn-unet - FP8 (E5M2):
--fp8_e5m2-unet
- VAE 模型精度:
- 由 ComfyUI 决定:无对应参数
- 全精度 (FP32):
--fp32-vae - 半精度 (FP16):
--fp16-vae - BF16:
--fb16-vae
- (禁用时) 使用向上采样法提高 XAttn 精度 (upcast-attention):
- Fooocus:
- (禁用时) 使用向上采样法提高 XAttn 精度 (upcast-attention):
--disable-attention-upcast - 通常模型精度:
- 由 Fooocus 决定:无对应参数
- 全精度 (FP32):
--all-in-fp32 - 半精度 (FP16):
--all-in-fp16
- 文本编码器 (Text Encoder) 模型精度:
- 由 Fooocus 决定:无对应参数
- 全精度 (FP32):
--clip-in-fp32 - 半精度 (FP16):
--clip-in-fp16 - FP8 (E4M3FN):
--clip-in-fp8-e4m3fn - FP8 (E5M2):
--clip-in-fp8-e5m2
- U-Net 模型精度:
- 由 Fooocus 决定:无对应参数
- BF16:
--unet-in-bf16 - 半精度 (FP16):
--unet-in-fp16 - FP8 (E4M3FN):
--unet-in-fp8-e4m3fn - FP8 (E5M2):
--unet-in-fp8-e5m2
- VAE 模型精度:
- 由 Fooocus 决定:无对应参数
- 全精度 (FP32):
--vae-in-fp32 - 半精度 (FP16):
--vae-in-fp16 - BF16:
--vae-in-bf16
- (禁用时) 使用向上采样法提高 XAttn 精度 (upcast-attention):
在 CPU 中运行 VAE☍
将 VAE 移动到 CPU 中运行,以牺牲性能的代价防止 VAE 阶段爆显存。
Note
该选项仅在 SD WebUI Forge / ComfyUI 中可用。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI Forge:
--vae-in-cpu - (启用时) ComfyUI:
--cpu-vae
激进提速策略☍
使用 FP8 精度进行计算,(Nvidia 显卡支持使用 FP8 精度进行计算,并且计算速度更快),在牺牲一定质量的情况下加速推理速度。
Note
- 该功能需要 Rtx 40 系及以上的 Nvidia 显卡,其他型号显卡不支持该功能。
- 在计算精度设置里可以看到 FP8 精度,但和该部分得 FP8 有些区别。在计算精度设置启用 FP8 后,实际运行时,模型是以 FP8 精度载入显存 / 内存中,在进行推理时,模型会进行一次上采样将计算精度提高到 FP16 后再进行计算,而不是保持 FP8 进行计算。启用激进提速策略后,计算时不再使用 FP16 精度进行计算,而是使用 FP8 精度进行计算。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) 激进提速策略:
--fast
使用共享显存☍
在 Nvidia 显卡公版驱动 大于等于 536.40 版本中,支持在专用 GPU 显存不足时使用共享 GPU 显存来补足,降低爆显存的概率。但是调用了共享显存后将会显著地降低出图速度,这时可以关闭共享显存来解决。
Note
关闭共享显存的前提是 Nvidia 显卡公版驱动的版本大于 546.01 或小于 536.40 版的公版驱动,非必要不建议使用旧版驱动。
Info
该选项是绘世启动器通过修改 Nvidia 控制面板中的配置来实现。手动手动实现方法:
1. 打开 NVIDIA 控制面板 -> 3D 设置 -> 管理 3D 设置 -> 程序设置。
2. 点击添加 -> 浏览,在 Windows 文件浏览器中找到运行环境中的python.exe(一般在你的 AI 运行环境路径/python/python.exe或者你的 AI 运行环境路径/venv/Scripts/python.exe),选中后点击打开进行添加。
3. 在指定该程序的设置值 -> CUDA - 系统内存回退政策,选择偏好无系统内存回退,最后点击应用保存设置。
Channels-last 内存优化☍
这个功能对性能的影响未知。
Warning
Channels-last 目前存在问题,启用后可能会带来减速。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--opt-channelslast - (启用时) SD WebUI AMDGPU:
--opt-channelslast - (启用时) ComfyUI:
--force-channels-last
模型哈希计算☍
在 SD WebUI 启动过程中,会计算 SD WebUI 模型文件夹中模型的哈希值并记录下来,但这个过程会花费一定的时间,在低速的硬盘上花费的时间更多,导致启动 SD WebUI 的时间增加。关闭这个选项可以加快 SD WebUI 的启动速度,但可能会导致 SD WebUI 的模型信息查看页面无法正常显示哈希值。
Info
该选项对应不同 WebUI 的启动参数:
- (禁用时) SD WebUI:
--no-hashing - (禁用时) SD WebUI AMDGPU:
--no-hashing - (禁用时) SD WebUI Forge:
--no-hashing - (禁用时) SD Next:
--no-hashing
Accelerate 多卡训练加速☍
这个设置是为了让 Dreambooth 模型训练插件支持多卡训练,但目前非常不建议在 SD WebUI 中进行任何的模型训练,如需训练模型,请使用专门的模型训练器。
Note
以下为专门的模型训练器:
SD-Trainer:https://github.com/Akegarasu/lora-scripts
Kohya GUI:https://github.com/bmaltais/kohya_ss
Kohya Scripts:https://github.com/kohya-ss/sd-scripts
OneTrainer:https://github.com/Nerogar/OneTrainer
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
python -m accelerate.commands.launch /path/to/launch.py - (启用时) SD WebUI AMDGPU:
python -m accelerate.commands.launch /path/to/launch.py - (启用时) SD Next:
python -m accelerate.commands.launch /path/to/launch.py
CUDA 内存分配方案☍
这个设置用于更换 Nvidia 显卡的 CUDA 内存分配方案,使用 CUDA 内置异步分配器可以提高性能,但需要 CUDA 版本大于 11.4。也就是说不仅 Nvidia 显卡驱动支持的 CUDA 版本要大于这个值,PyTorch 中所带的 CUDA 版本也要大于这个值。
注意:CUDA 内存分配方案主要涉及在 GPU 上如何有效地管理内存。CUDA 提供了多种内存类型,包括全局内存、共享内存、常量内存和纹理内存等,每种内存类型都有其特定的用途和性能特点。
全局内存(Global Memory):这是 GPU 上最大的内存空间,所有线程都可以访问。全局内存的访问速度相对较慢,因此需要尽量减少全局内存的访问次数,并尽量对全局内存进行连续访问以利用缓存机制。
共享内存(Shared Memory):共享内存是线程块(block)内所有线程共享的内存,访问速度比全局内存快得多。共享内存非常适合用于线程块内的数据交换和临时存储。合理使用共享内存可以显著提高程序的性能。
常量内存(Constant Memory):常量内存也是所有线程共享的,但只能用于只读操作。常量内存的访问速度对于相同的地址访问是很快的,但由于其只读特性,不适合用于需要频繁更新的数据。
纹理内存(Texture Memory):纹理内存也是一种只读存储,但它是为纹理查找操作优化的。它支持缓存和线性过滤,适用于访问具有二维或多维结构的数据,如图形、图像处理等领域。
寄存器(Registers):每个线程都有一定数量的寄存器用于存储变量。寄存器的访问速度最快,但由于数量有限,需要合理规划变量的使用以避免寄存器溢出。
局部内存(Local Memory):当寄存器不足时,变量会被自动分配到局部内存中。局部内存实际上是全局内存的一部分,但通过特定的硬件机制进行访问,因此速度比直接访问全局内存快一些。不过,使用局部内存也会增加内存占用和访问延迟,因此应尽量减少局部内存的使用
Note
查看显卡驱动支持的 CUDA 的版本:
在绘世启动器的高级选项中点击右上角的启动命令提示符,输入nvidia-smi并回车,此时看到 CUDA Version 后面的数字为 Nvidia 显卡驱动最高支持的 CUDA 版本,当然 CUDA 支持向下兼容,低于这个版本的 CUDA 也能使用。
Info
该选项使用PYTORCH_CUDA_ALLOC_CONF环境变量控制:
- PyTorch 原生分配器:
garbage_collection_threshold:0.9,max_split_size_mb:512 - CUDA 内置异步分配器 (CUDA 11.4+):
backend:cudaMallocAsync
预览图生成模式☍
设置生成图片过程中图片的预览算法。
Note
这个选项仅存在于 ComfyUI / Fooocus 中。
Info
该选项对应不同 WebUI 的启动参数:
- ComfyUI:
- 关闭预览:
--preview-methon none - 自动:
--preview-methon auto - Latent2RGB:
--preview-methon latent2rgb - TAESD:
--preview-methon taesd
- 关闭预览:
- Fooocus:
- 关闭预览:
--preview-methon none - 自动:
--preview-methon auto - Latent2RGB:
--preview-methon latent2rgb - TAESD:
--preview-methon taesd
- 关闭预览:
智能显存优化☍
使模型尽量保留在显存中而不是自动从显存中卸载,以节省显存和内存的交换时间。
Note
这个选项仅存在于 ComfyUI / Fooocus 中。
Info
该选项对应不同 WebUI 的启动参数:
- (禁用时) SD WebUI Forge:
--always-offload-from-vram - (禁用时) ComfyUI:
--disable-smart-memory - (禁用时) Fooocus:
--always-offload-from-vram
稳定计算☍
使用速度较慢的稳定算法以尽量保持图片的一致性。
Note
这个选项仅存在于 ComfyUI / Fooocus 中。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI Forge:
--pytorch-deterministic - (启用时) ComfyUI:
--deterministic - (启用时) Fooocus:
--pytorch-deterministic
Forge 设置☍
将 SD WebUI 中的模型共享给 SD WebUI Forge。
Info
该选项对应的命令行参数:--forge-ref-a1111-home <SD WebUI 路径>
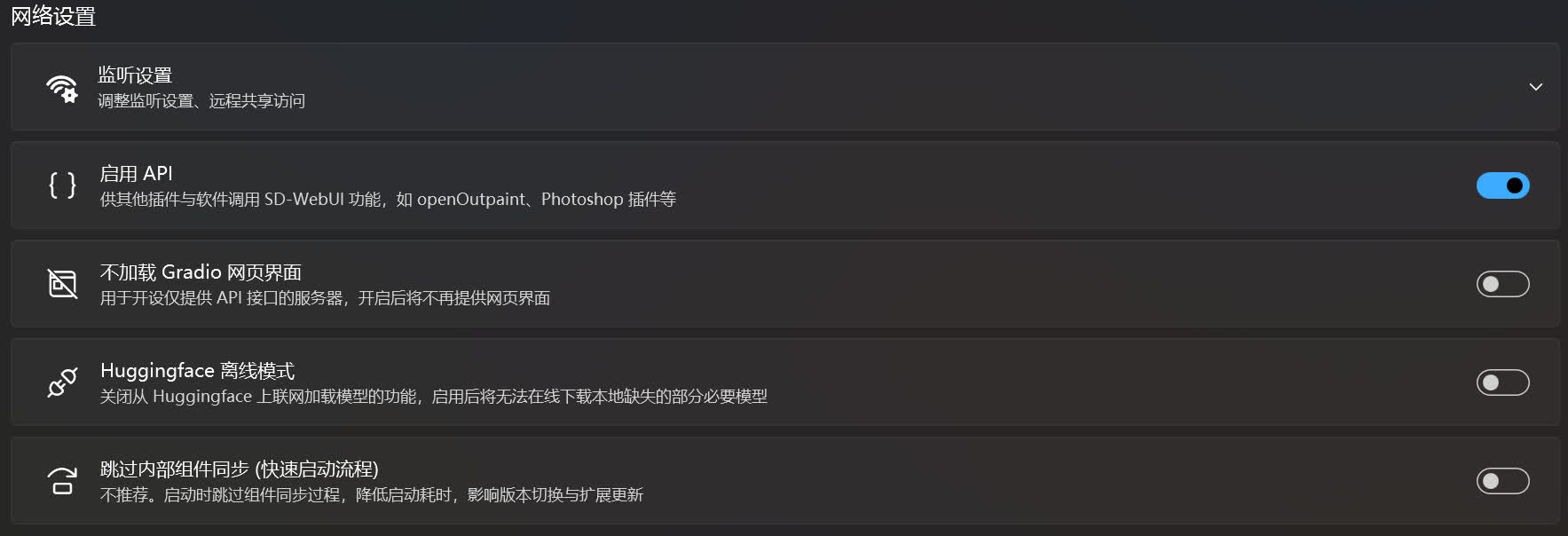
网络设置☍
监听设置☍
这是用于调整 SD WebUI / ComfyUI / ... 的网页界面地址和远程连接的设置。
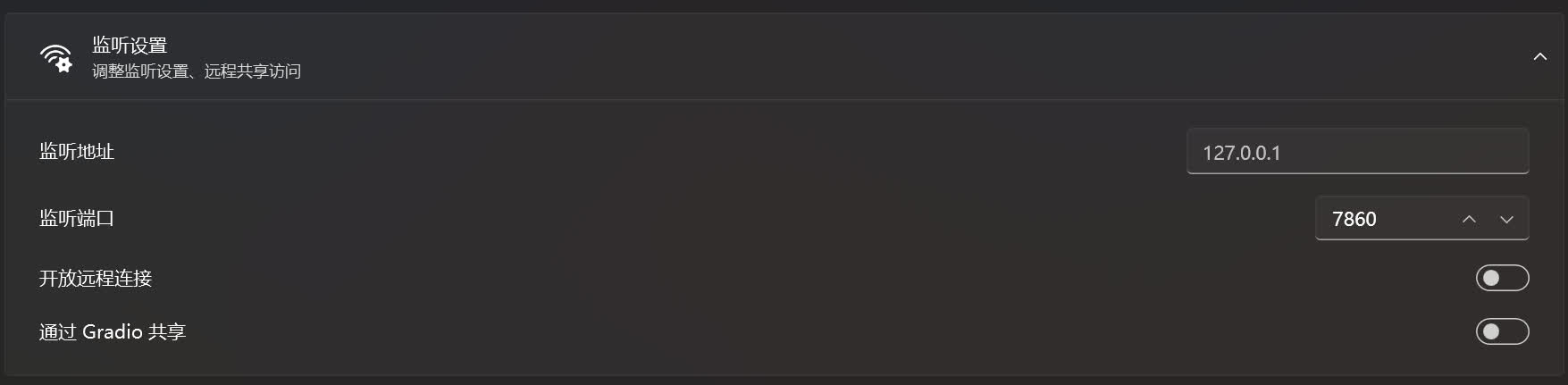
监听地址为网页界面的地址,默认值为 127.0.0.1,这个设置绝大多数情况下不需要调整,调整后有可能会造成电脑的防火墙拦截导致无法访问。
监听端口为网页界面地址所对应的端口,如果这里填写的端口被某个软件占用,将会导致无法正常启动网页界面。可尝试关闭占用端口的软件或者调整监听端口。
启用开放远程链接后可以使和该设备处在同一个局域网的设备能够访问网页界面,使用该设备的局域网IP + 监听端口即可访问。
通过 Gradio 共享是通过 Gradio 官方的内网穿透服务,使该设备的网页界面能够被非局域网的设备访问。启用后在绘世启动器的控制台中可以看到对应的访问地址,一般为 https://xxxxxxxxxxxxxxxxxx.gradio.live。
Note
开放远程链接后启动时控制台内显示的IP为 0.0.0.0,且启动完成后不会自动打开浏览器。
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:
- 监听地址:
--server-name <IP 地址> - 监听端口:
--port <端口号> - (启用时) 开放远程连接:
--listen - (启用时) 通过 Gradio 共享:
--share
- 监听地址:
- SD WebUI AMDGPU:
- 监听地址:
--server-name <IP 地址> - 监听端口:
--port <端口号> - (启用时) 开放远程连接:
--listen - (启用时) 通过 Gradio 共享:
--share
- 监听地址:
- SD WebUI Forge:
- 监听地址:
--server-name <IP 地址> - 监听端口:
--port <端口号> - (启用时) 开放远程连接:
--listen - (启用时) 通过 Gradio 共享:
--share
- 监听地址:
- SD Next:
- 监听地址:
--server-name <IP 地址> - 监听端口:
--port <端口号> - (启用时) 开放远程连接:
--listen - (启用时) 通过 Gradio 共享:
--share
- 监听地址:
- ComfyUI:
- 监听地址:
--listen <IP 地址> - 监听端口:
--port <端口号> - (启用时) 开放远程连接:
--listen(如果设置了监听地址,则是--listen <IP 地址>)
- 监听地址:
- Fooocus:
- 监听地址:
--listen <IP 地址> - 监听端口:
--port <端口号> - (启用时) 开放远程连接:
--listen(如果设置了监听地址,则是--listen <IP 地址>) - (启用时) 通过 Gradio 共享:
--share
- 监听地址:
- SD-Trainer:
- 监听地址:
--host <IP 地址> - 监听端口:
--port <端口号> - Tensorboard 监听地址:
--tensorboard-host <IP 地址> - Tensorboard 监听端口:
--tensorboard-port <端口号> - 开放远程连接:
--listen
- 监听地址:
启用 API☍
开放 SD WebUI 的 API 接口以提供给其他软件扩展使用。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--api - (启用时) SD WebUI AMDGPU:
--api - (启用时) SD WebUI Forge:
--api - (启用时) SD Next:无对应参数
不加载 Gradio 网页界面☍
禁用加载网页界面,只开放 API 接口,用于开设服务器。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--nowebui - (启用时) SD WebUI AMDGPU:
--nowebui - (启用时) SD WebUI Forge:
--nowebui - (启用时) SD Next:无对应参数
Huggingface 离线模式☍
禁用从 Huggingface 上下载模型,启用后 SD WebUI 将无法自动下载缺失的必要模型。
Info
该选项使用HF_HUB_OFFLINE环境变量设置,启用时,该值设置为1。
跳过内部组件同步 (快速启动流程)☍
禁用 SD WebUI 内部组件同步,可加快启动速度,但会影响 SD WebUI 的版本切换和扩展更新。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--skip-install - (启用时) SD WebUI AMDGPU:
--skip-install - (启用时) SD WebUI Forge:
--skip-install - (启用时) SD Next:
--skip-requirements --skip-extensions --skip-git --skip-torch
用户体验设置☍
这是有关使用体验的设置。
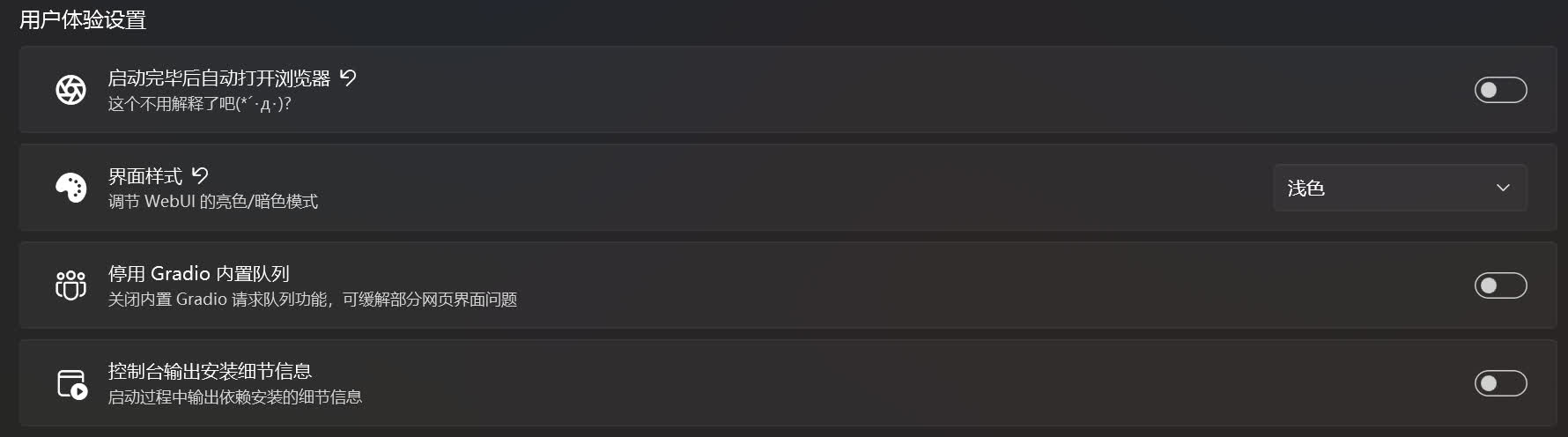
启动完毕后自动打开浏览器☍
这个就不用多说了。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--autolaunch - (启用时) SD WebUI AMDGPU:
--autolaunch - (启用时) SD WebUI Forge:
--autolaunch - (启用时) SD Next:
autolaunch - (启用时) ComfyUI:
--auto-launch - (启用时) Fooocus:
--in-browser
多用户模式☍
运行多个用户同时使用同个实例。
Note
该选项仅在 ComfyUI 出现。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) ComfyUI:
--multi-user
界面样式☍
调整网页界面的主题,如浅色主题和深色主题。
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:
- 深色:
--theme dark - 浅色:
--theme light
- 深色:
- SD WebUI AMDGPU:
- 深色:
--theme dark - 浅色:
--theme light
- 深色:
- SD WebUI Forge:
- 深色:
--theme dark - 浅色:
--theme light
- 深色:
- SD Next:
- 深色:无对应参数
- 浅色:无对应参数
- Fooocus:
- 深色:
--theme dark - 浅色:
--theme light
- 深色:
停用 Gradio 内置队列☍
用于关闭 Gradio 内置的请求队列功能,可能可以缓解部分界面的问题,不过有时候关闭后可能会造成新的问题。
Note
SD WebUI,Fooocus 的界面基于 Gradio 制作,所以有 Gradio 内置队列这个功能。Gradio 为了让多设备同时访问同一个网页界面,设计了队列功能以保证多设备访问时任务能够有序的运行。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--no-gradio-queue - (启用时) SD WebUI AMDGPU:
--no-gradio-queue - (启用时) SD WebUI Forge:
--no-gradio-queue - (启用时) SD Next:
--disable-queue
控制台输出安装细节信息☍
显示启动过程中 Pip 安装依赖时的具体信息,一般用于调试。
Note
SD WebUI 在启动时会检查自身和扩展的依赖是否齐全并安装,但是在默认情况下并不会显示出来。
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:通过
WEBUI_LAUNCH_LIVE_OUTPUT环境变量控制,启用时该值为1。 - SD WebUI AMDGPU:通过
WEBUI_LAUNCH_LIVE_OUTPUT环境变量控制,启用时该值为1。 - SD WebUI Forge:通过
WEBUI_LAUNCH_LIVE_OUTPUT环境变量控制,启用时该值为1。
多用户模式☍
允许多个用户同时使用同一个实例,提供类似 SD WebUI 的多用户功能。
Note
这个选项仅存在于 ComfyUI / Fooocus 中。
启动器特性设置☍
这是绘世启动器的特性设置。

启用云端页面汉化☍
为网页界面进行汉化,当 SD WebUI / ComfyUI 未安装汉化扩展时可使用该功能进行汉化。
Info
该功能由绘世启动器热补丁系统提供。
Torch 文件保存编码修正☍
解决 PyTorch 保存模型文件时出现文件名乱码的问题。
Info
该功能由绘世启动器热补丁系统提供。
安全性设置☍
这是有关安全的设置。
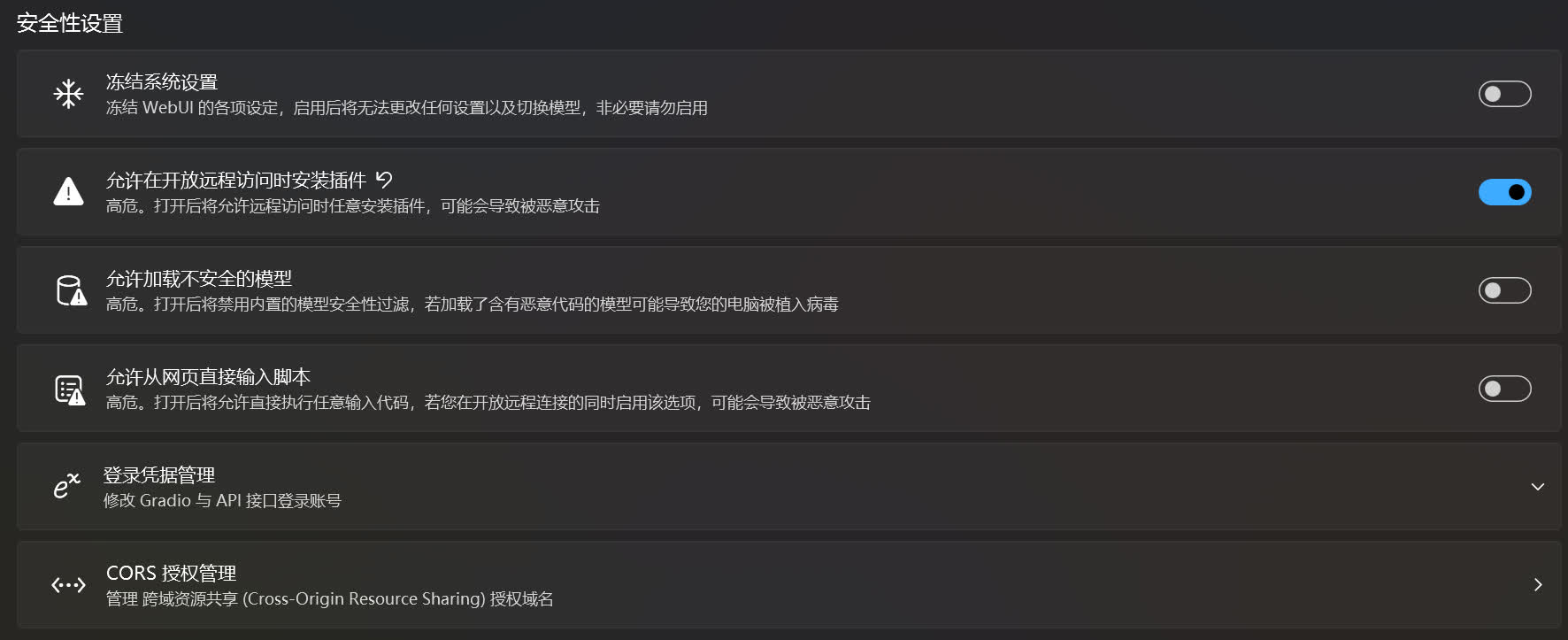
冻结系统设置☍
禁用 SD WebUI 的修改设置功能。当在启动开放远程连接后将网页界面共享给他人使用,但是又不想网页界面的设置被他人修改,就可以启用这个设置。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--freeze-settings - (启用时) SD WebUI AMDGPU:
--freeze-settings - (启用时) SD WebUI Forge:
--freeze-settings - (启用时) SD Next:
--freeze-settings
允许在开放远程访问时安装插件☍
解除在启动开放远程访问后对安装扩展的限制。
Note
这个限制是 SD WebUI 设计的安全措施,当在绘世启动器的高级选项->监听设置里启用开放远程连接或者通过 Gradio 共享时,SD WebUI 为了防止他人访问网页界面后通过安装恶意插件来实现攻击,将禁用 SD WebUI 的安装扩展功能。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--enable-insecure-extension-access - (启用时) SD WebUI AMDGPU:
--enable-insecure-extension-access - (启用时) SD WebUI Forge:
--enable-insecure-extension-access - (启用时) SD Next:
--enable-insecure
允许加载不安全的模型☍
禁用加载模型时的安全检查。SD WebUI 在加载模型时将检查模型的安全性,若该模型不安全则停止加载。禁用安全检查后 SD WebUI 将不会检查模型的安全性,但可嫩会导致加载模型后被模型内的恶意代码攻击。
Note
在早期的模型中,模型的格式一般是pt或者ckpt等,但是这些模型格式可能会被植入恶意代码,当这样的模型被加载的时候,里面内置的恶意代码将被执行,导致不良的后果。为了解决模型安全问题,HuggingFace 开发了safetensors格式,解决模型被恶意代码的问题。个人建议下载模型的时候最好选择safetensors格式的模型。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--disable-safe-unpickle - (启用时) SD WebUI AMDGPU:
--disable-safe-unpickle - (启用时) SD Next:
--disable-safe-unpickle
允许加载从网页直接输入脚本☍
允许在 SD WebUI 中运行任意的代码。但是当在启动开放远程连接后可能会出现他人在 SD WebUI 界面执行恶意代码,使设备受到恶意攻击。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--allow-code - (启用时) SD WebUI AMDGPU:
--allow-code - (启用时) SD WebUI Forge:
--allow-code - (启用时) SD Next:
--allow-code
登陆凭证管理☍
为 Gradio 共享的网页设置账号密码验证,防止他人随意访问 Gradio 共享的链接。
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:
- 管理 Gradio 账号密码:
--gradio-auth 账号1:密码1,账号2:密码2,... - 管理 API 账号密码:
--api-auth 账号1:密码1,账号2:密码2,...
- 管理 Gradio 账号密码:
- SD WebUI AMDGPU:
- 管理 Gradio 账号密码:
--gradio-auth 账号1:密码1,账号2:密码2,... - 管理 API 账号密码:
--api-auth 账号1:密码1,账号2:密码2,...
- 管理 Gradio 账号密码:
- SD WebUI Forge:
- 管理 Gradio 账号密码:
--gradio-auth 账号1:密码1,账号2:密码2,... - 管理 API 账号密码:
--api-auth 账号1:密码1,账号2:密码2,...
- 管理 Gradio 账号密码:
- SD Next:
- 管理 Gradio 账号密码:
--gradio-auth 账号1:密码1,账号2:密码2,... - 管理 API 账号密码:
--api-auth 账号1:密码1,账号2:密码2,...
- 管理 Gradio 账号密码:
CORS 授权管理☍
管理跨域资源共享授权域名。
Info
该选项对应不同 WebUI 的启动参数:
- SD WebUI:
--cors-allow-origins 域名1,域名2,... - SD WebUI AMDGPU:
--cors-allow-origins 域名1,域名2,... - SD WebUI Forge:
--cors-allow-origins 域名1,域名2,... - SD Next:
--cors-allow-origins 域名1,域名2,...
其他设置☍
这是调整其他设置的地方。
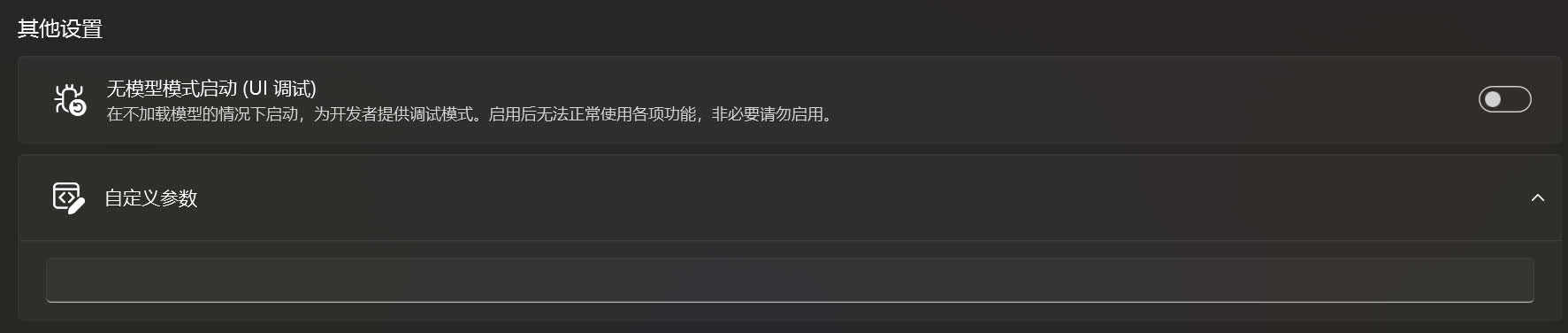
无模型模式启动 (UI 调试)☍
在不加载模型的情况下启动 SD WebUI,用于调试,启用后将无法正常使用功能。
Info
该选项对应不同 WebUI 的启动参数:
- (启用时) SD WebUI:
--ui-debug-mode - (启用时) SD WebUI AMDGPU:
--ui-debug-mode - (启用时) SD WebUI Forge:
--ui-debug-mode - (启用时) SD Next:无对应参数
自定义参数☍
这是用于自定义 SD WebUI / ComfyUI / ... 的启动参数。
Note
关于启动参数的说明:
AUTOMATIC1111/stable-diffusion-webui:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings
vladmandic/automatic:https://github.com/vladmandic/automatic/wiki/CLI-Arguments
lllyasviel/Fooocus:https://github.com/lllyasviel/Fooocus?tab=readme-ov-file#all-cmd-flags
ComfyUI 需要在命令提示符中输入python main.py -h并回车来查看