文生图☍
在了解 InvokeAI 的模型管理器并添加模型后,下面就介绍如何在 InvokeAI 中生成图片。
Note
在 InvokeAI 的设置中,建议勾选用户界面选项中的启用信息弹窗,启用后将鼠标移动到某个参数上时 InvokeAI 将显示该参数的作用。如果需要详细的生成进度显示,可以启用显示进度详情。
快捷键☍
InvokeAI 为了方便操作,支持使用快捷键打开某些功能,在 InvokeAI 左下角的设置选项可以看到快捷键,打开后可以查看 InvokeAI 的快捷键对应的功能。

提示词☍
正向提示词填写想要 AI 生成的内容,并且尽量详细,使 AI 生成的图片更加准确,下面是一段完整描述画面的提示词。
welchino, yanyo \(ogino atsuki\), kita \(kitairoha\), ciloranko,
1girl,solo,cherry blossoms,pink flower,hair flower,hair ribbon,cat ears,animal ear fluff,hair ribbon,pink eyes,grey hair,short hair,two side up,bangs,hair between eyes,blush,fang,long sleeves,bow,white shirt,puffy sleeves,collared shirt,sleeves past wrists,black bow,puffy long sleeves,blue vest,sweater vest,pleated skirt,black skirt,barefoot,
swing,one eye closed,smile;d,open mouth,sitting,looking at viewer,
outdoors,tree,cherry blossoms,petals,flower,outstretched arm,light rays,
full body,
masterpiece,best quality,newest,
第一行为画师串,用于调整画风,画师串是否生效由模型决定。第二行描写了人物的特征,第三行描写人物的动作,第四行描写的环境,第五行描写了镜头,最后一行为质量提示词。通常这样详细的提示词描述可以让出图效果更好。
负面提示词描写不想让 AI 画出来的东西,下面是比较通用的负面提示词,在大部分情况下都可以使用。如果有其他不想让 AI 画出来的东西,可以在这段负面提示词的基础上进行修改。
low quality,worst quality,normal quality,text,signature,jpeg artifacts,bad anatomy,old,early,copyright name,watermark,artist name,signature
高级提示词使用☍
如果需要让某个提示词的影响效果增强或者降低提示词的影响效果,可以调整提示词权重,下面是一段例子。
+ / - 符号可以增加 / 减少提示词的权重,每加一个+号将为提示词的权重乘以 1.1,每加一个-号将为提示词的权重除以 0.9。
则上面的提示词中flower sea的权重为 1.0,tree的权重为 1.21,river的权重为 0.9。
使用符号调整提示词权重并不直观,所以可以使用数字设置提示词的权重,则上面的提示词可以修改为下面的形式。
如果想要将某部分的提示词含义混合在一起,可以使用提示词混合功能,下面是一段使用提示词混合的提示词。
上面的提示词将会使landscape painting以trees为主,sunset scene以warm tones为主,两个部分提示词的影响效果相同。
提示词模板☍
当有提示词中有常用的提示词,比如画风提示词,此时可以创建一个提示词模板方便调用,在正向提示词框的上方可以看到选择提示词模板选项,打开后可以看到 InvokeAI 内置的部分提示词模板,选择后即可使用,或者点击 + 号添加自己的提示词模板,输入模板名称和提示词后点击保存即可。
提示词模板只能选择一个,如果需要选择多个,只能选择其中一个提示词模板后。点击将选定的模板内容合并到当前提示中,此时模板中的提示词将加载到提示词框中,这样就可以再选择另一个提示词模板。
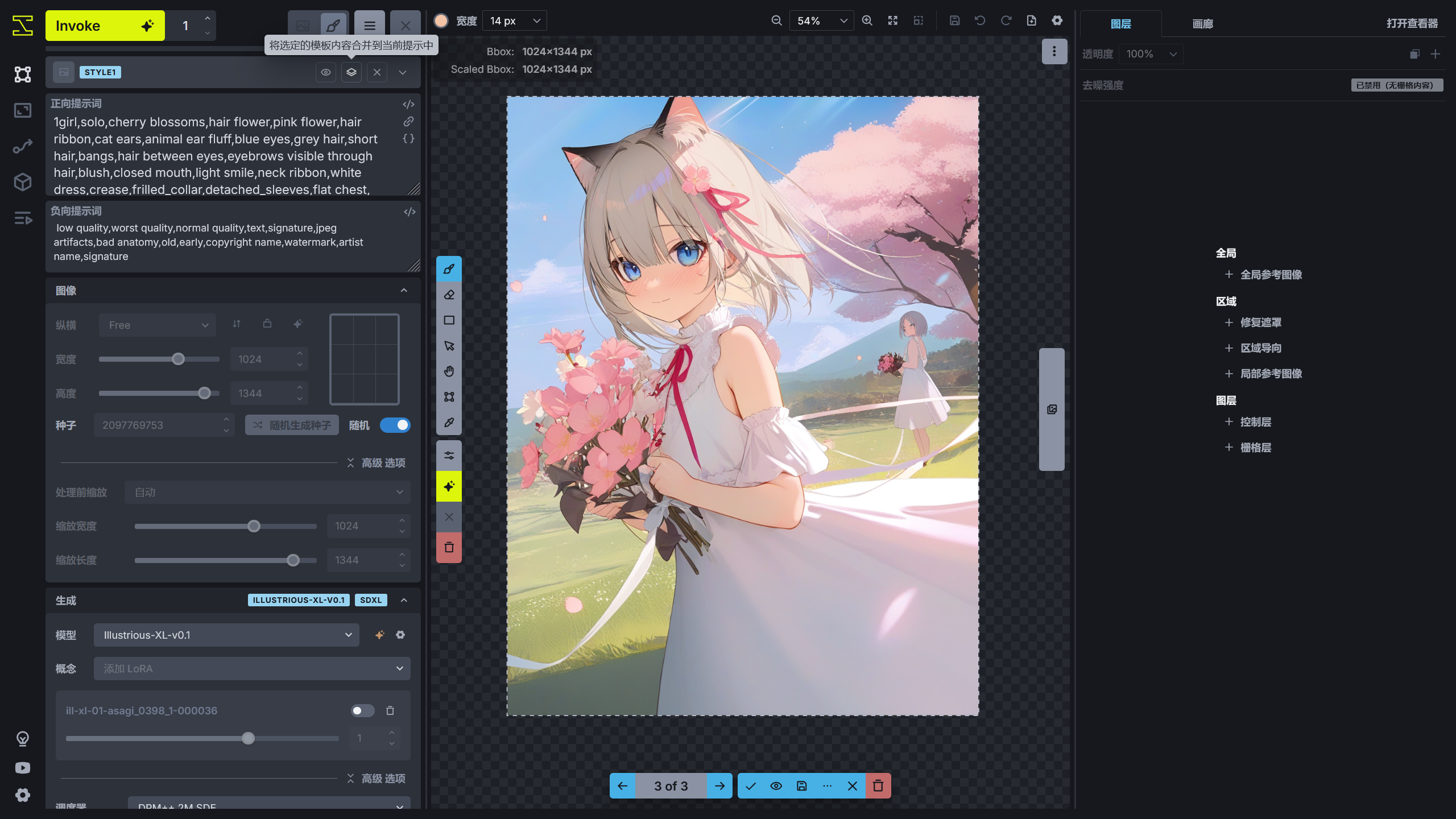
生成参数☍
纵横可以选择预设的宽高比,宽度和高度设置生成图片的分辨率,通常根据模型适合生成的分辨率进行设置,这里使用的模型是 Illustrious-XL-v0.1,属于 Stable Diffusion XL 模型,适合的分辨率为 1024 x 1024,使用接近该分辨率或者比这个分辨率大一些的分辨率通常会有比较好的效果,比如使用 1024 x 1344 的分辨率。
种子设置初始的噪声形状,通常保持随机即可。当种子相同时,并且其他参数相同时,每次生成的图片将相同。
模型设置使用的大模型,这里选择前面下载的 Illustrious-XL-v0.1,概念设置要使用的 LoRA 模型,这里先跳过该选项。
点开生成选项的高级选项可以看到调度器、步数、CFG 等级设置。InvokeAI 和 Stable Diffusion WebUI、ComfyUI 有些区别,在 InvokeAI 中采样器选项和调度器选项是合为一起的。
不同的调度器需要不同的步数,并且出图的效果也有一些差别,可自行测试。这里使用 DPM++ 2M SDE,步数设置为 20。
CFG 等级控制图像和提示词的匹配程度。这个值越高,出图更接近提示词(不同的模型效果不同),过高的值可能会导致出图的质量下降,不同的模型需要不同的提示词引导系数,需要自行测试。Illustrious-XL-v0.1 模型设置 CFG 等级为 5 即可。
在高级选项中可以设置 VAE,通常该选项选择默认 VAE 即可,即使用大模型自带的 VAE。VAE 精度建议设置为 FP16降低 VAE 阶段显存的消耗,在 VAE 阶段出现 NaN 的情况下再尝试使用 FP32。
CFG 重缩放倍数适用于使用零终端信噪比训练的模型,通常保持默认即可。
无缝平铺 X / Y 轴通常不需要使用。
生成☍
左上角为 InvokeAI 的生成选项,点击 Invoke 按钮可以进行图片生成,如果该按钮为灰色,可以将鼠标移到按钮上,InvokeAI 将展示哪些参数不满足生成的要求并根据提示进行修改。如果需要生成多张图片,可以多次点击 Invoke 按钮。
Invoke 按钮旁边的数字用于设置迭代数,也就是生成图片的数量。
迭代数右边的选项设置生成结束后图片保存的位置,可选择发送到图库或者发送到画布,这里就选择发送到图库。
如果想要取消当前生成图片的任务,点击取消当前项目即可。
查看生成结果☍
在前面选择了发送到图库,所以查看生成的进度需要在查看器中查看,点击右上角的打开查看器将从画布切换到查看器。
点击画廊可以查看保存下来的图片。
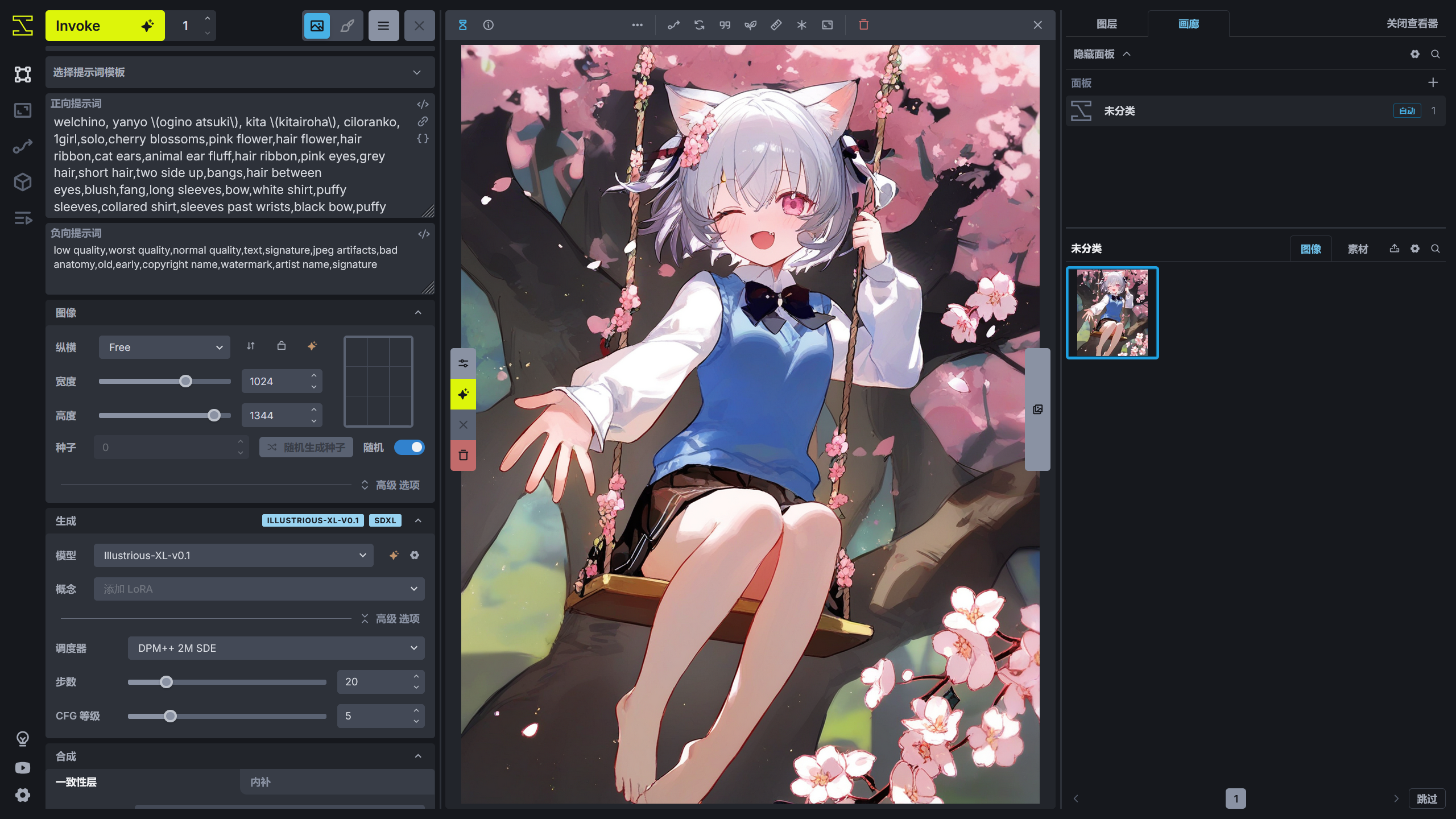
图片信息查看☍
如果需要查看 InvokeAI 生成的图片的参数时,点击查看器上方的信息按钮或者按下 I 键可以查看图片的生成信息。
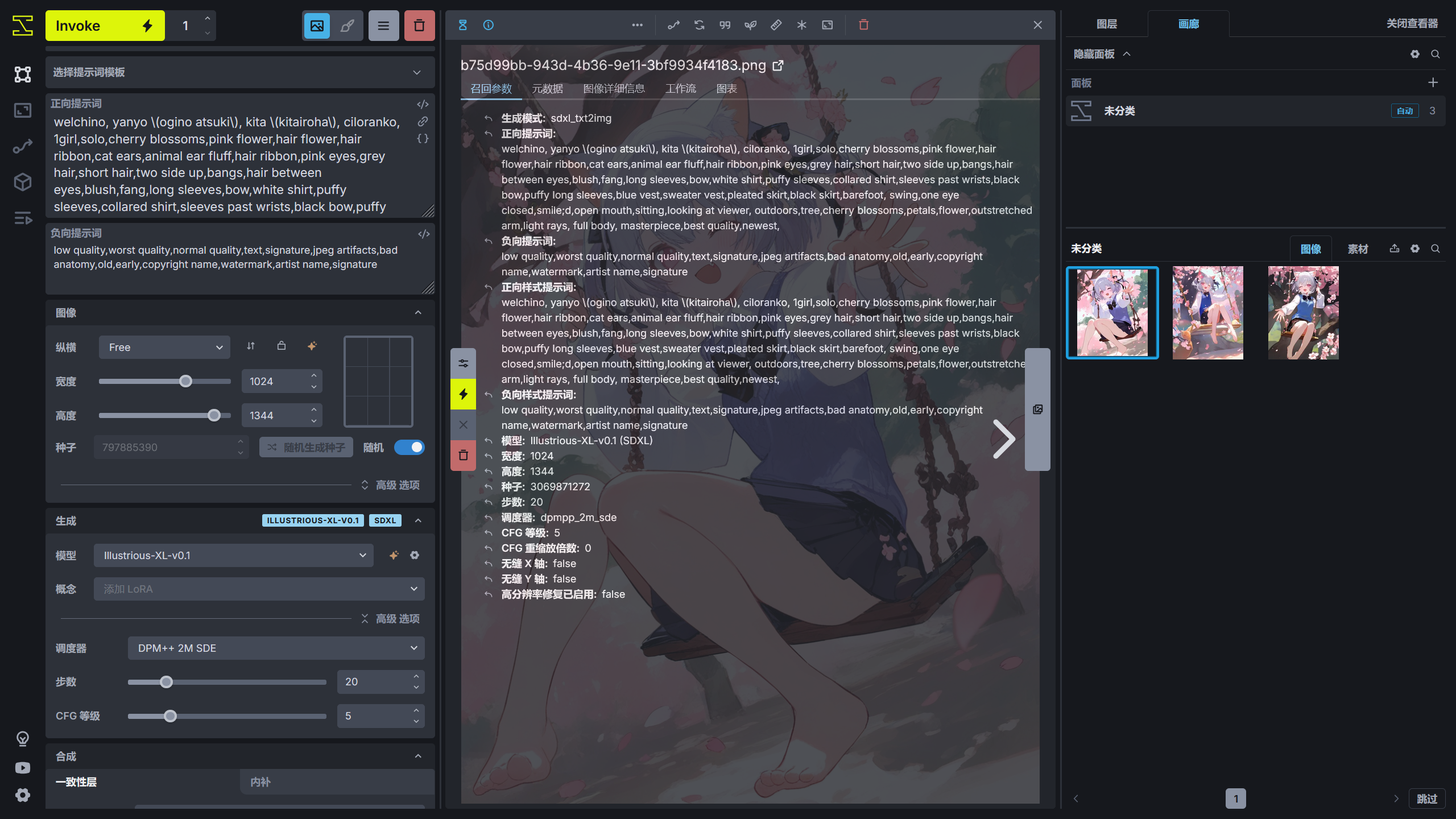
在不同信息的左侧有个箭头,点击后可以将图片的参数发送到左侧对应的图片生成参数选项中。
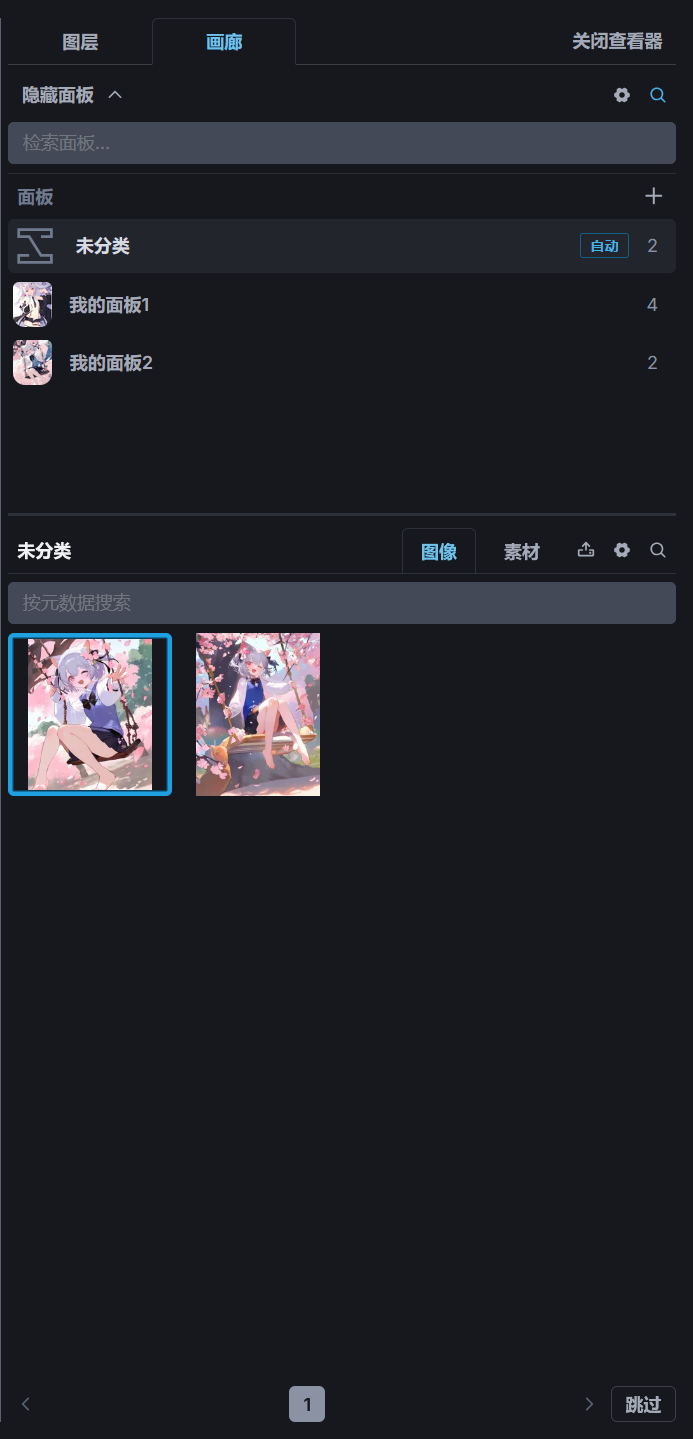
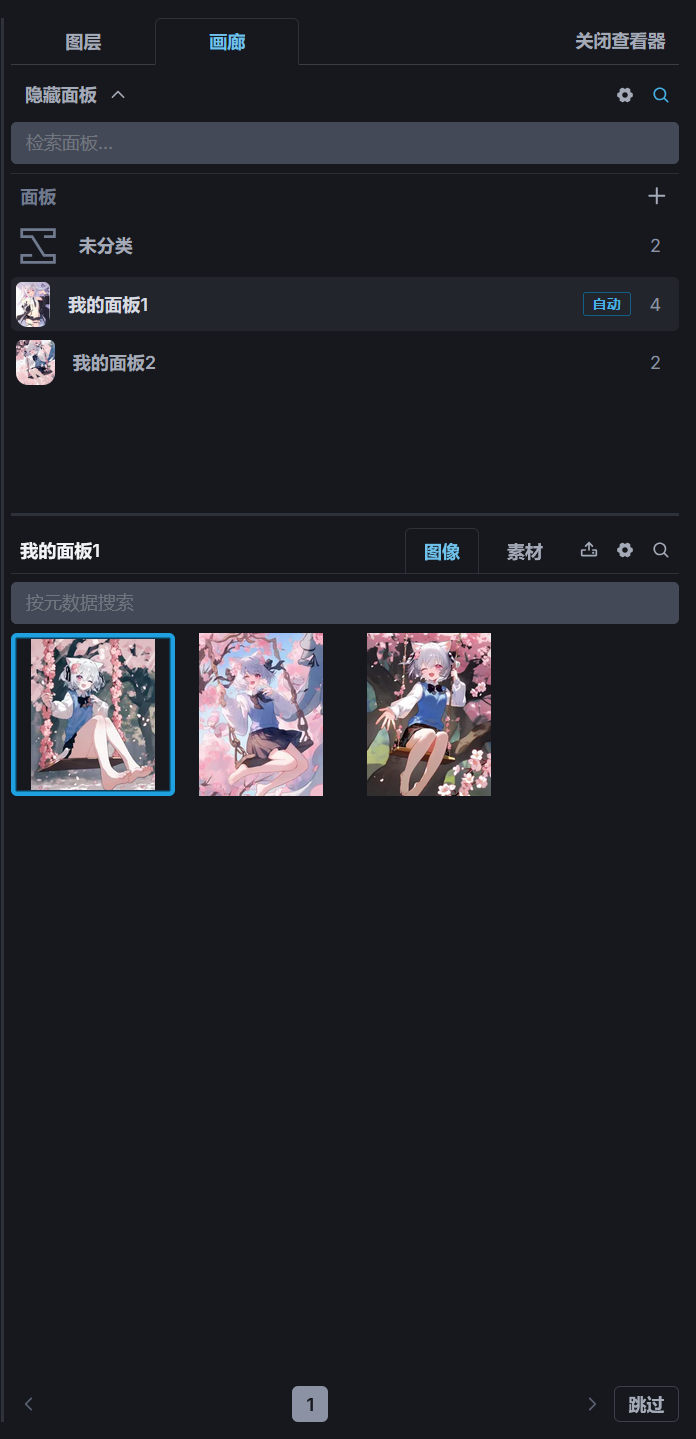
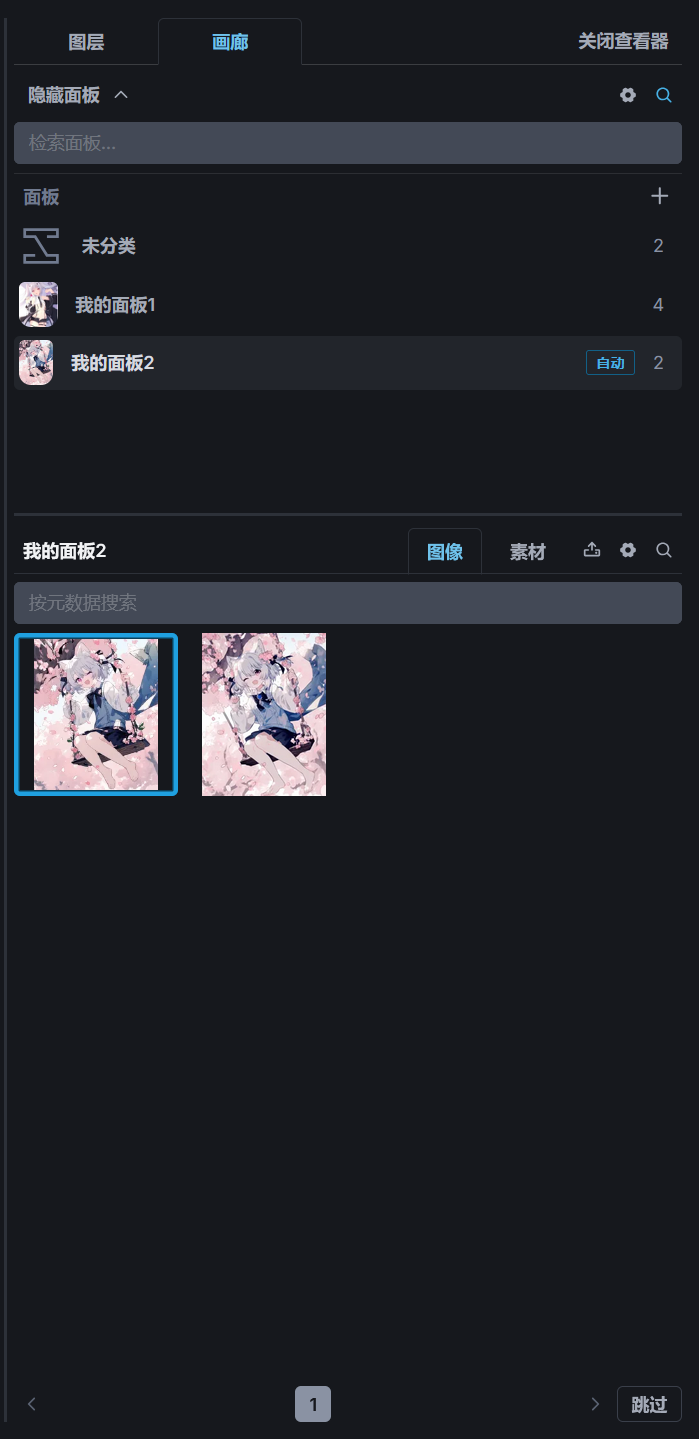
画廊☍
画廊可以查看 InvokeAI 保存的图片,如果需要对比画廊中的两张图片的差别时,可以在画廊中选中一张图片,并按住 Alt 键,选择另一张图片,此时将打开图片对比功能。

画廊支持对图片进行分类,当图片数量过多时,可以创建不同的分类对图片进行分类存放,点击面板选项里的+号可以创建新的分类,将鼠标移动到分类面板的名称上将显示一个按钮用于修改名称。
创建分类面板后,用鼠标拖动分类面板下的图片可以将图片移动到另一个分类面板中。
 |
 |
 |
|---|---|---|
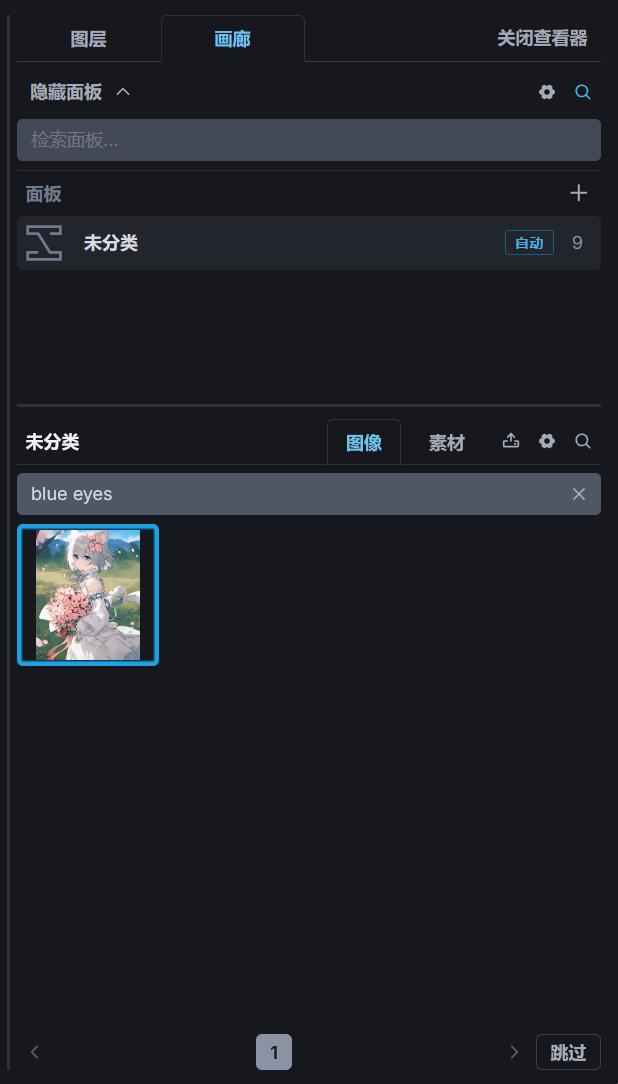
画廊还支持搜索图片,点击图片列表右上角的🔍︎按钮,输入关键词并回车后即可进行搜索,搜索功能将根据关键词查找图片中的元数据是否有匹配关键词的并展示出来。
 |
 |
|---|---|
Note
图片的元数据可在查看器中查看,点击 InvokeAI 右上角的打开查看器后,在画廊中选择一张图片,再按下 I 键打开图片信息,选择元数据即可查看图片的元数据。元数据包含图片的生成参数,如提示词,分辨率等。
画廊还支持导入图片素材用于创作,点击画廊中的📤︎按钮可以打开系统的文件管理器上传图片,或者将图片从系统的文件管理器拖动一张图片到 InvokeAI 的界面中,图片将自动添加到素材中。
LoRA 应用☍
当大模型不能通过提示词的方式实现自己想要的效果时,可以使用 LoRA 模型来实现。
在左侧参数的模型选项下方有个概念选项,这里可以添加要使用的 LoRA 模型。当 LoRA 和大模型兼容时,LoRA 模型可以被添加,否则将被 InvokeAI 标记为灰色,表示 LoRA 不兼容当前选择的大模型。
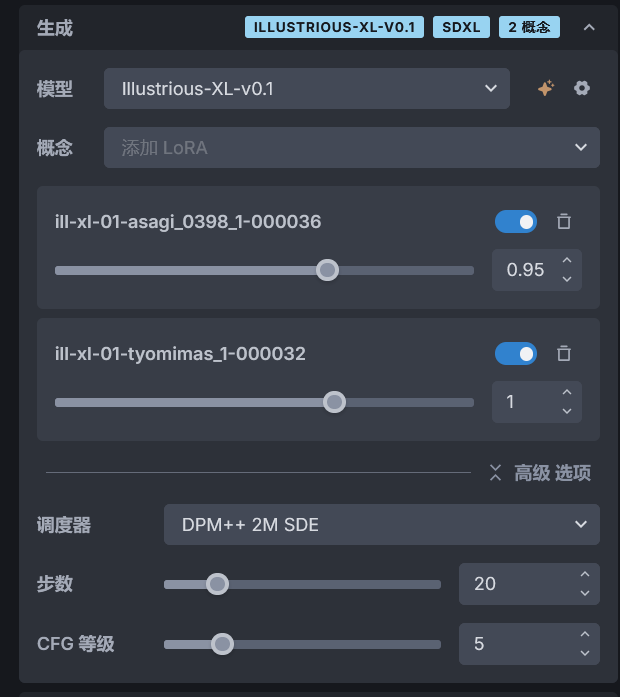
添加 LoRA 模型后,可以设置 LoRA 模型的权重。越高的模型权重,LoRA 模型的影响效果越强,但过高的权重可能会造成生成的图片崩坏,当出现崩坏时就需要降低 LoRA 模型的权重。
LoRA 模型通常在训练该 LoRA 模型时使用的大模型上表现最好,在别的大模型上可能会导致效果减弱或者不产生效果。一般在下面 LoRA 模型的地方,LoRA 模型的作者会告知建议在哪个大模型上使用该 LoRA 模型。